Getting started With Git - A Simple Beginner's Guide
| 13 min read
I'm not going to mess around with pre-waffle here, like what is Git? and all that jazz. Fact of the matter is, if you're on this page I'm confident that you probably know what Git is already.
The aim of this post is to give you enough to do the basics with Git and get going. From there you can continue to learn more if you need it.
The rest of this post will assume you're using GitHub for your remote repositories, but all of the Git commands are the same no matter which service you use.
Git clone
This first thing you need in order to get started with Git, is to clone a repository locally. This will be a local working copy of your data, which you will manage.
So let's say we have a repository on GitHub called example (inventive name, I know), log into your GitHub account and navigate to your example repository so we can clone it.
To clone the repository, click on the green Code button and copy the link.
In the example below I'm using SSH to clone my repository. By default GitHub uses HTTPS. I personally prefer SSH as it's generally regarded as more secure. If you want to do the same, follow this guide.
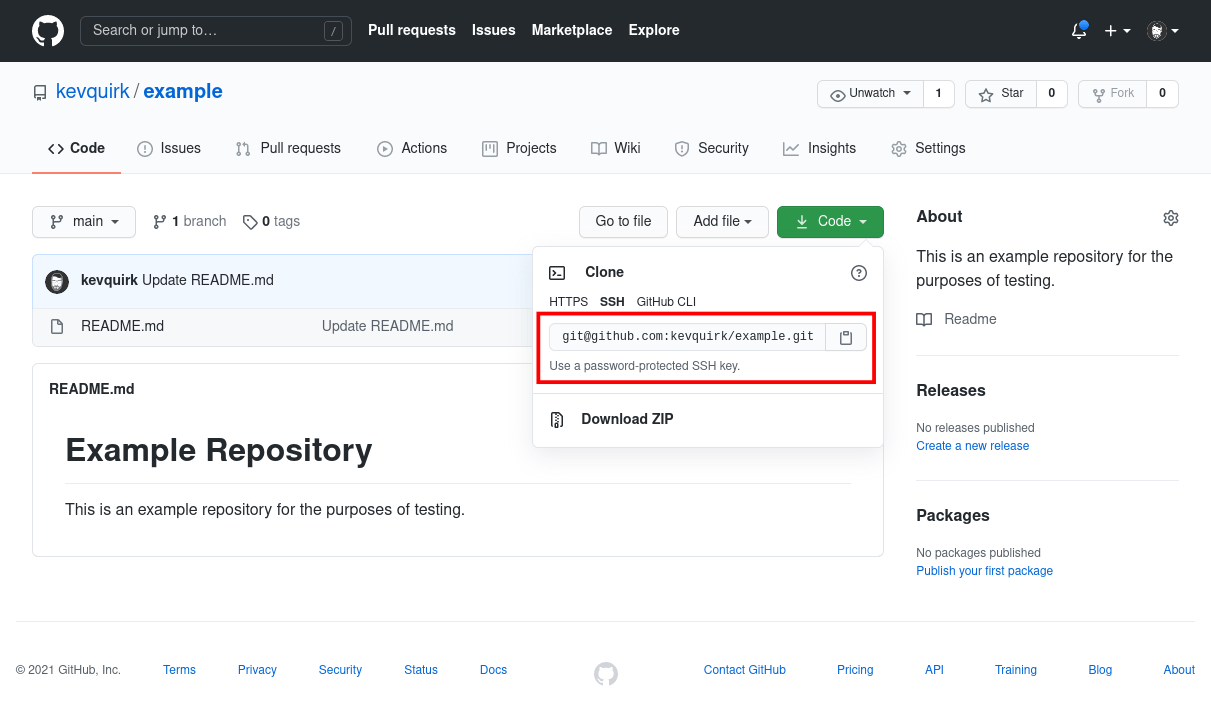
Copy the clone link for your repository and head over to a terminal window. First, cd into the directory that you wish to store your local copy of the repository, then run the git clone command followed by the link you copied:
cd ~/GitHub
git clone git@github.com:kevquirk/example.gitThis will then clone the repository to your local machine. The output should look something like this:
kev@thinkpad:~$ cd GitHub/
kev@thinkpad:~/GitHub$ git clone git@github.com:kevquirk/example.git
Cloning into 'example'...
remote: Enumerating objects: 6, done.
remote: Counting objects: 100% (6/6), done.
remote: Compressing objects: 100% (4/4), done.
remote: Total 6 (delta 0), reused 0 (delta 0), pack-reused 0
Receiving objects: 100% (6/6), done.
Working locally with Git
Fantastic! We now have our example repository cloned locally and we can start working on it. From here you can do pretty much anything you like - you can add, change or delete the contents of the repository and nothing will be changed at GitHub until you do a git push
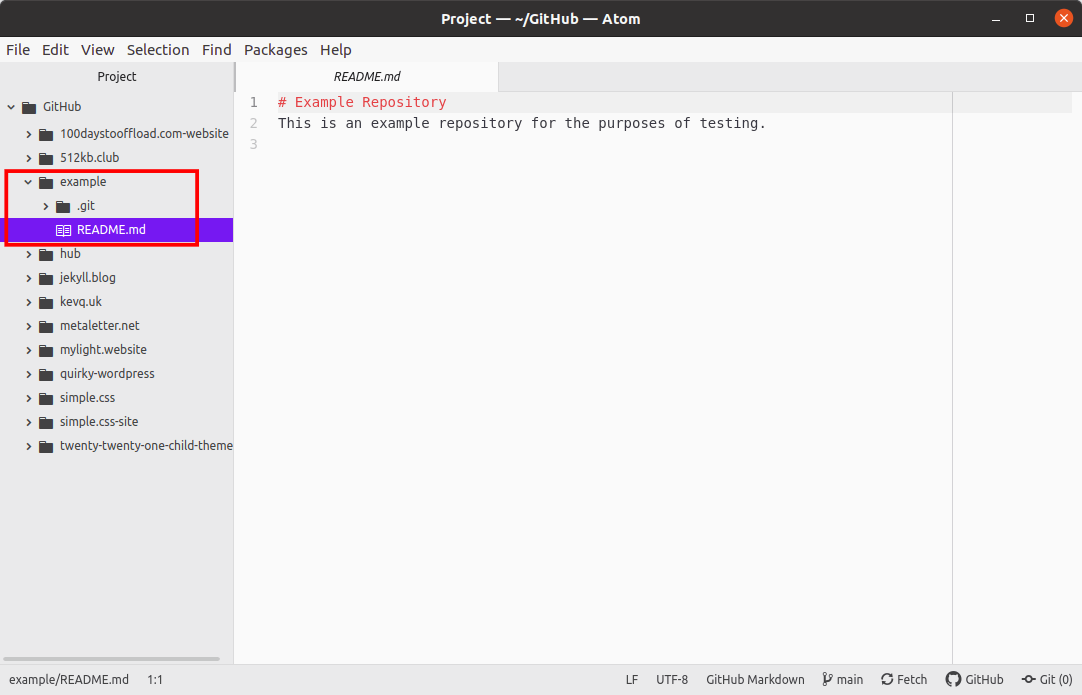
So let's fire up a text editor (I personally use Atom) and start working with the example repository. At the moment, the repository is looking pretty sparse, as it only contains a README.md file:
Adding files to Git
Next thing we're going to do is add a file to our example repository. Create new file called about.md and populate it with some text. Once you're happy, save the file.
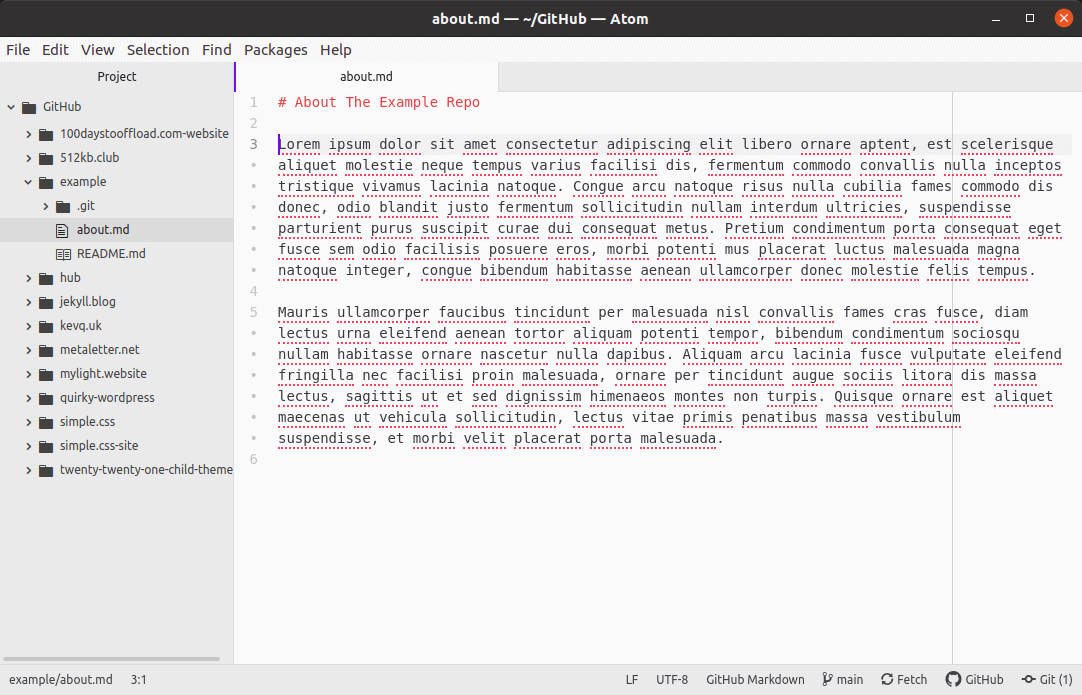
If you now go back to your terminal window and run a git status on the example repo, you should see something that looks like this:
kev@thinkpad:~/GitHub/example$ git status
On branch main
Your branch is up-to-date with 'origin/main'.
Untracked files:
(use "git add <file>..." to include in what will be committed)
about.md
nothing added to commit but untracked files present (use "git add" to track)Git is telling us here that we have added the about.md file, but it is untracked. This means that our new file hasn't been staged, so isn't tracked by Git. Let's stage about.md so that it's tracked:
git add about.mdIf we run another git status the output should now have changed to something like this:
kev@thinkpad:~/GitHub/example$ git status
On branch main
Your branch is up-to-date with 'origin/main'.
Changes to be committed:
(use "git restore --staged <file>..." to unstage)
new file: about.mdSo about.md is no longer listed as untracked, but Git is now telling us that we need to commit the changes that we have staged.
If you have multiple files to add to your Git repo, use git add * instead. This will add all untracked files within your repository.
Committing changes
We're really getting started with Git now, aren't we! The next thing we need to do is commit our changes to Git.
But what does 'committing changes' mean, Kev?
- Pretty much everyone
Yeah, I get it. The technical verbiage that Git uses can be confusing. But the process basically goes like this:
1. Create a new file that is untracked.
2. You `add` the file to the repo so it's now tracked. This is called “staging”.
3. The staged file is `committed` to the local repository, which effectively writes that change into the history of the repository.
4. Finally, changes are `pushed` to the remote repository. In our case that's GitHub.Ok, with that digression out of the way, let's get back to getting started with Git. We now need to commit the about.md file to our repository:
git commit -m "Added about.md file"The -m flag allows us to add a commit message. This is very important as it allows us to look back over the history of changes (if needed) so we can make sense of what they were.
The output of the git commit should look something like this:
kev@thinkpad:~/GitHub/example$ git commit -m "Added about.md file"
[main e5fc6eb] Added about.md file
1 file changed, 5 insertions(+)
create mode 100644 about.mdPushing changes
The only thing left to do now is push the changes to GitHub so they are available not only as a kind of backup, but also for anyone else who may be working on this repository.
git pushOnce again, the output of your git push command should look something like this:
kev@thinkpad:~/GitHub/example$ git push
Enumerating objects: 4, done.
Counting objects: 100% (4/4), done.
Delta compression using up to 4 threads
Compressing objects: 100% (3/3), done.
Writing objects: 100% (3/3), 898 bytes | 898.00 KiB/s, done.
Total 3 (delta 0), reused 0 (delta 0)
To github.com:kevquirk/example.git
53837c4..e5fc6eb main -> mainIf we now flip back to GitHub and take a look at the example repository, we should see that the about.md file has been added:
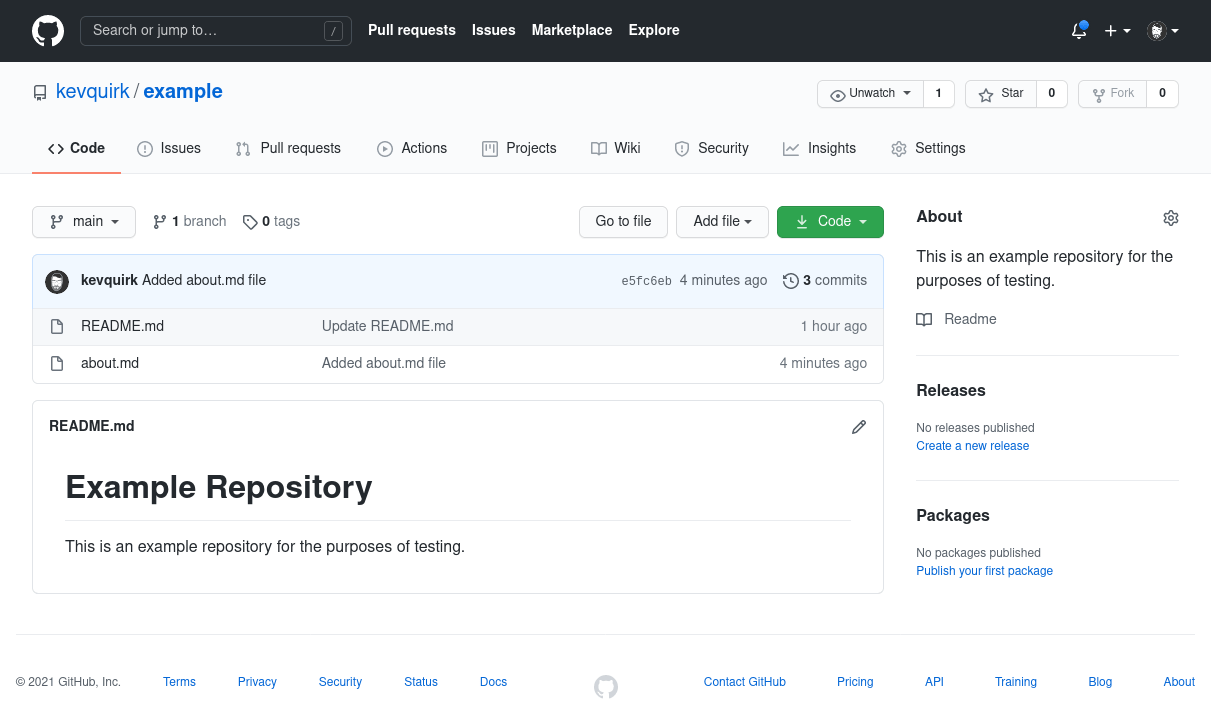
You will also notice that we can see the commit message next to about.md too. This helps when reviewing files as it will allow you to see which files where pushed with which commit.
Pulling updates with Git
Let's say that someone else has contributed a new file to our example repository and you want to pull down that contribution.
If we look on our GitHub page, new-file.md has been added, but we don't have that in our local repository:
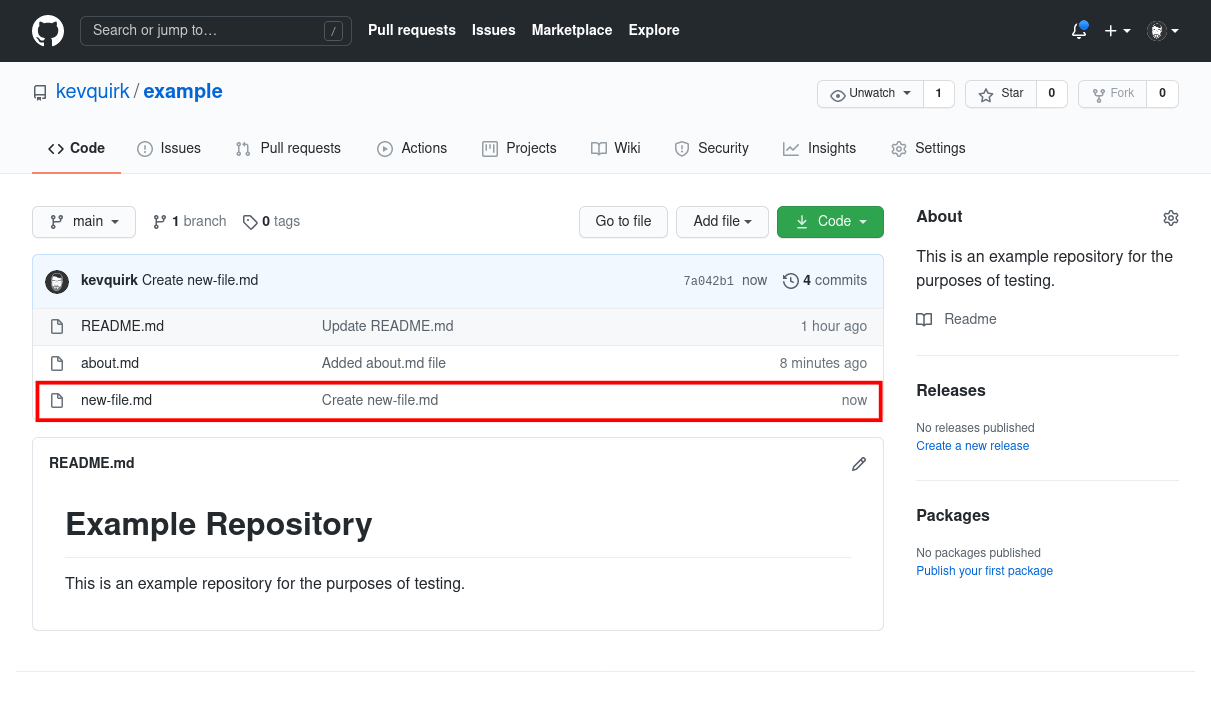
To get the latest changes from GitHub, we simply run the following command:
git pullThis will pull down the latest changes from the example repository on GitHub and the output will look something like this:
kev@thinkpad:~/GitHub/example$ git pull
remote: Enumerating objects: 4, done.
remote: Counting objects: 100% (4/4), done.
remote: Compressing objects: 100% (3/3), done.
remote: Total 3 (delta 0), reused 0 (delta 0), pack-reused 0
Unpacking objects: 100% (3/3), 749 bytes | 749.00 KiB/s, done.
From github.com:kevquirk/example
e5fc6eb..7a042b1 main -> origin/main
Updating e5fc6eb..7a042b1
Fast-forward
new-file.md | 3 +++
1 file changed, 3 insertions(+)
create mode 100644 new-file.mdIf we take a look at Atom again, we should now be able to see the new file:
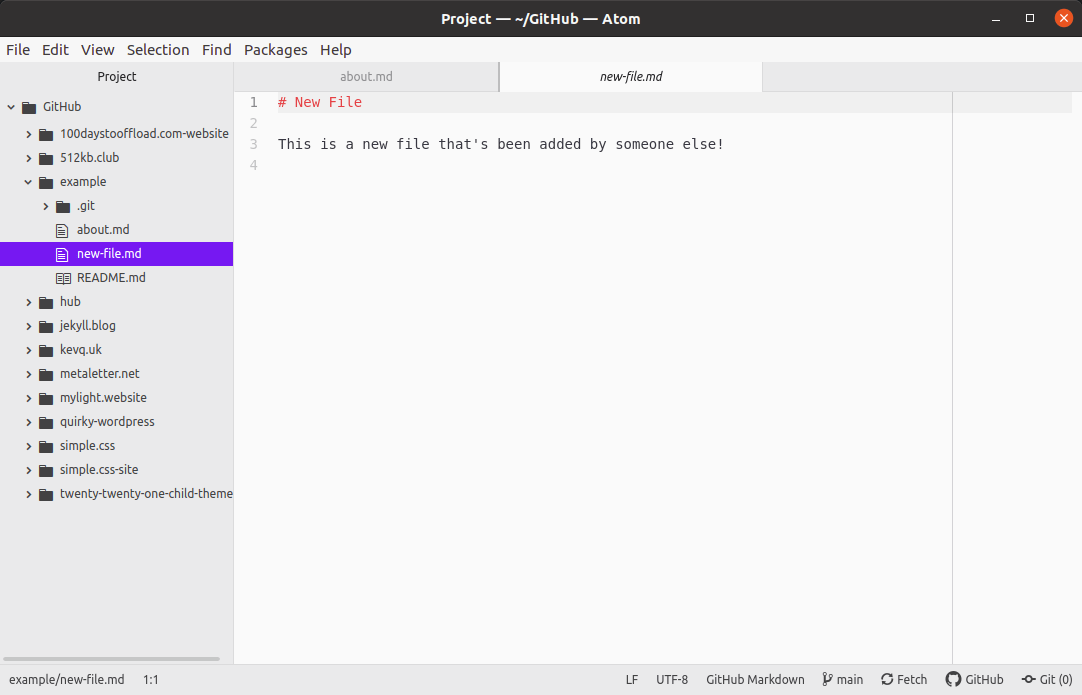
If we then wanted to work on this file ourselves, we simply make changes then run the git add, git commit & git push commands again.
git add *
git commit -m "Updated new-file.md with new info"
git pushWorking with branches
The info above is enough to get started with Git, but now we're going to take our use of Git to the next level by introducing branches.
How the hell do trees come into this??
- All the people
Branches allow you to work on a copy of your main code in a safe environment. For example, I use Git to manage the theme for this website and I have 2 branches; dev and main. The main branch is the production branch that is used on the live site.
I use the dev branch for making changes to my theme on my staging site. So I play around and make changes to my staging site on the dev branch, then once I'm happy for them to go live on the production site, I merge those changes into main.
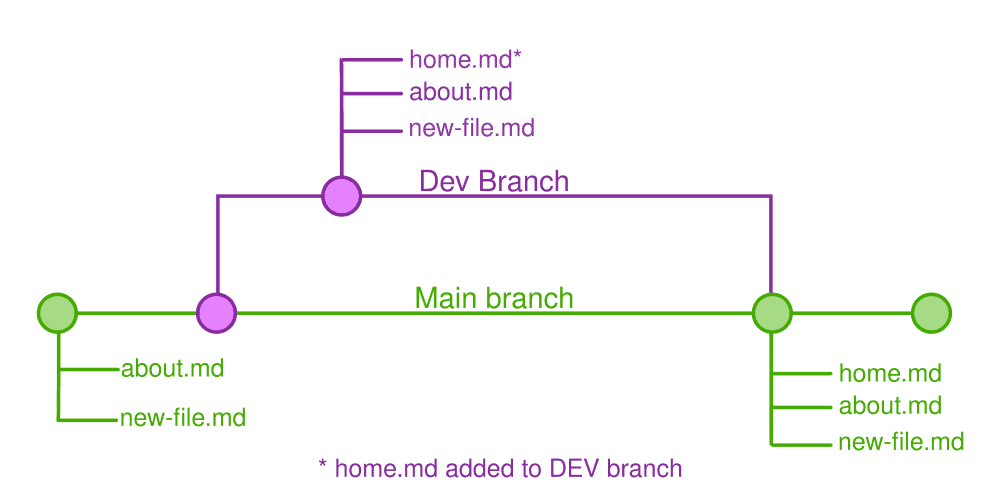
In the example above you will see that I have added home.md on the dev branch, then merged it into main. Let's head back to our terminal and do that shall we?
Changing branches
The first thing we need to do is change to the dev branch. You do that with the following command:
git checkout -b devThe -b flag here will create a new branch called dev and switch to it. The output on your terminal should be something like this:
kev@thinkpad:~/GitHub/example$ git checkout -b dev
Switched to a new branch 'dev'From here we can make changes, additions and deletions as normal, but all this work will be done in dev, not main.
I've created a file called home.md so lets stage, commit and push that change to dev. This time though, our push command will be a little different as we want to tell GitHub we're pushing to dev:
git add *
git commit -m "Added home.md"
git push --set-upstream origin devThe output of the new dev push command should look something like this:
kev@thinkpad:~/GitHub/example$ git push --set-upstream origin dev
Enumerating objects: 4, done.
Counting objects: 100% (4/4), done.
Delta compression using up to 4 threads
Compressing objects: 100% (3/3), done.
Writing objects: 100% (3/3), 404 bytes | 404.00 KiB/s, done.
Total 3 (delta 0), reused 0 (delta 0)
remote:
remote: Create a pull request for 'dev' on GitHub by visiting:
remote: https://github.com/kevquirk/example/pull/new/dev
remote:
To github.com:kevquirk/example.git
* [new branch] dev -> dev
Branch 'dev' set up to track remote branch 'dev' from 'origin'.Now we're working in the dev branch on GitHub too. So if you want to push additional changes, you only need to use the standard git push command.
Merging branches
So we've been doing lots of work on the home.md file and we now want to merge it into main. There's a couple of ways of doing this, but the easiest is to do it from a terminal.
All you need to do is flip back to the main branch, then run the merge command to merge changes from dev to main. Finally we push the changes to GitHub:
# Switch back to main branch
git checkout main
# Merge changes from dev
git merge dev
# Push changes
git pushNotice how we didn't use the -b flag to switch back to the main branch here? That's because the main branch already exists. We only need -b when flipping to a new branch. If we want to flip back to dev at this point, all we need to do is run git checkout dev as we have already created this branch previously.
If we now take a look at our main branch on GitHub, we should see our new home.md file:
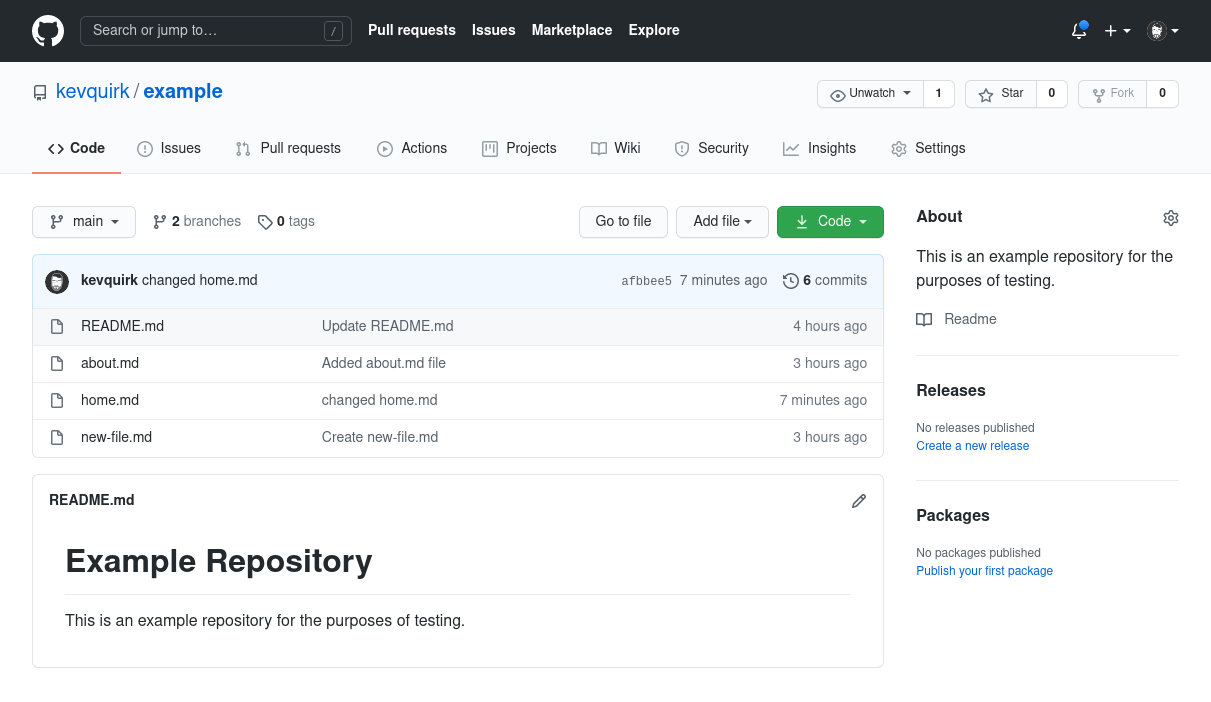
Reverting a change
So let's say you've been working away on your Git repository and you commit a change that adds some text to about.md. Problem is, you've now decided you no longer want that text to be on the page.
Now you could just delete the text do another git push, but if you're working with code and there are multiple changes, reverting an entire commit may be a better solution.
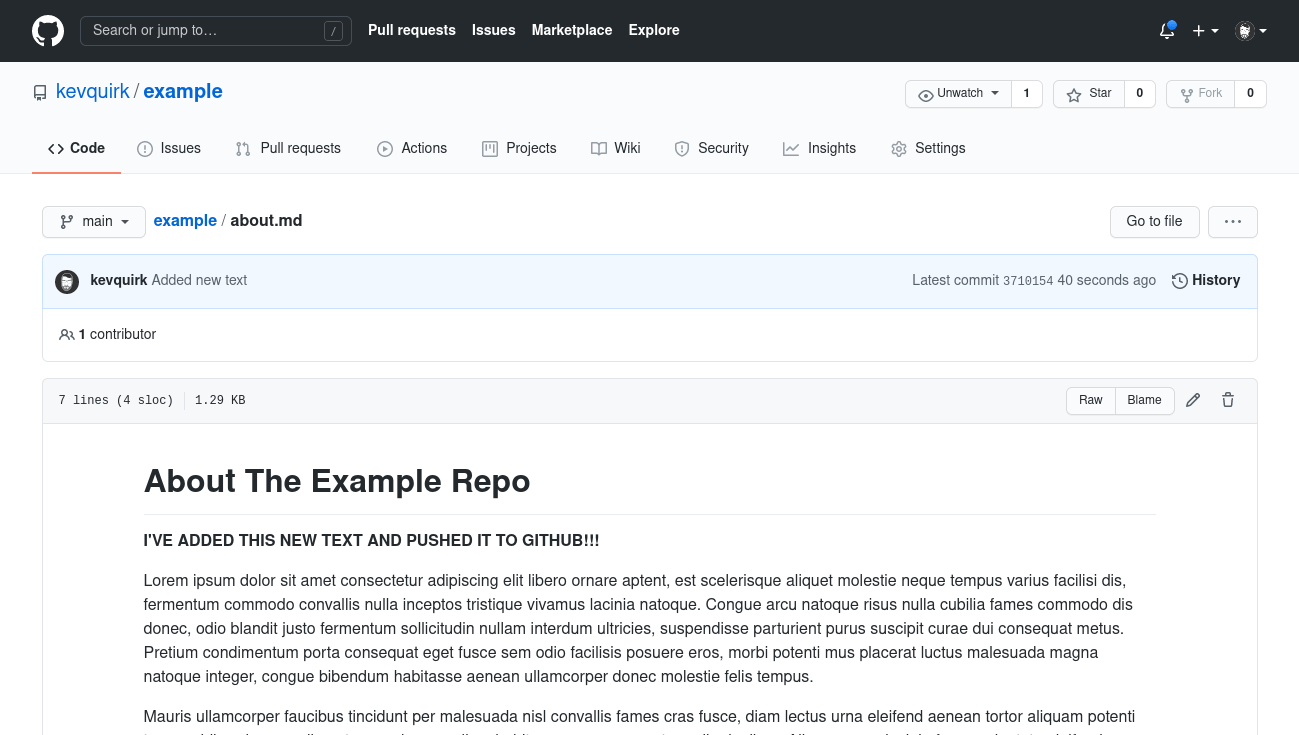
In the image above I've added a string of bold text below the title and committed it to my example repository with a commit message of Added new text.
In order to revert this change, we need to find the hash of the commit. To do that, we head to a terminal window and run the following command:
git log --pretty=onelineThe output of the git log command will look something like this:
kev@desktop:~/GitHub/example$ git log --pretty=oneline
371015469f5303244fd4096f7189898e60547f1a (HEAD -> main, origin/main, origin/HEAD) Added new text
afbbee514a4e9148fd12644c3f24e7fcf92d2488 (origin/dev) changed home.md
0cdee70d3457e4d07ef549e9fd1ead94eb09f8bd Added home.md
7a042b1bfad0db6050732992255c7a08c595c4a0 Create new-file.md
e5fc6ebc43c4984cb735df824e42a6cfbac46b84 Added about.md file
53837c4f72d32b56bedbdf2b492c28465c4f0811 Update README.md
e6db6b162289487d31becdbd11688305d8df97f0 Initial commit
The last commit we did is at the top of the list and is shown by the commit message Added new text. This commit has a hash of 371015469f5303244fd4096f7189898e60547f1a.
To revert the commit, take the first 5 characters of the hash and run the following command:
git revert <first 5 characters>So the correct command will look like this:
git revert 37101When you run this command you will be asked to provide a new commit message. Git defaults to “Revert [previous commit message]” which is usually fine. Once you're happy with the new commit message your output should look like this:
kev@desktop:~/GitHub/example$ git revert 37101
[main d02c55c] Revert "Added new text"
1 file changed, 2 deletions(-)Now we need to git push the change back to GitHub and if we check the about.md file, we should see that the additional string of text is gone:
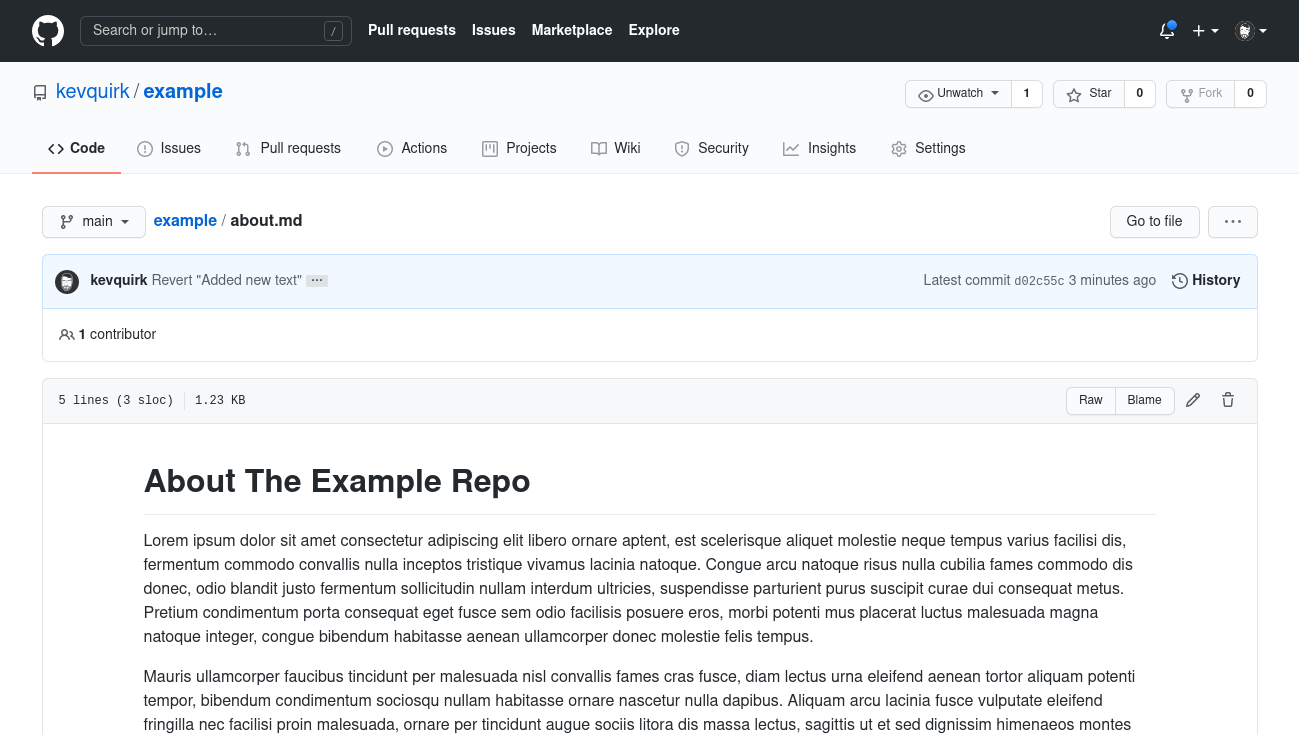
Ta da! We just reverted a commit. Good job!
You can now get started with Git
This should be enough to get you started with Git and give you an understanding of what the basics of using it are.
From here there are a tonne of other things you can learn to do in Git, like using GitHub Actions to add additional integrations. I'd strongly recommend taking a look at the official Git documentation if you want to learn more.
Hopefully this post will help some of you get started with Git. Please remember, this is just the bare basics - there's a tonne more to learn!
Now go forth and become a Git experts, my intrepid explorers!
Subscribe for more!
You don't have to keep coming back here to read my latest waffle. There's a couple of way to subscribe to receive updates whenever I publish new content.